Twitter Premium Search APIを使ってツイートを集めた

はじめに
大学の研究で機械学習を用いて文章生成を行うために、大量のテキストデータが欲しかったのでそのコーパスとしてツイートを集めました。
Developerアカウントの作成後ツイート取得まで、色々手こずったので備忘録として書いておきます。
Twitter API
Twitter APIにはSandbox、Premium、Enterpriseの3種類があり、それぞれ使える機能も異なります。詳細については割愛します。
今回はPremiumのFull-Archiveを利用しました。
アカウント作成
Developerアカウントを持っていない場合はApply for access – Twitter Developersからアカウントを作成してください。
認証キー取得
アカウント作成後、DeveloperアカウントのDashboardの右上ドロップダウン「Apps」→「Create an app」
アプリ名や概要を入力します。requiredと書かれている項目は必須項目なので必ず全て埋めてください。
入力後「Create」→ 作成したアプリの「Detail」→「Keys and tokens」よりConsumer KeyとAccess tokenを確認し、控えておいてください。
認証キーファイル作成
取得した認証キーをあらかじめ1つのファイルにまとめておく必要があるので、ファイルを作成します。
search_tweets_api: account_type: premium endpoint: https://api.twitter.com/1.1/tweets/search/fullarchive/dev.json consumer_key: #CONSUMER_KEY consumer_secret: #CONSUMER_SECRET
account_typeは利用するAPIを選択するので「premium」を指定してください
endpointは検索に利用するエンドポイントを記述します。
consumer_keyとconsumer_seccretは前項にて取得したキーを入力してください。
ツイート取得
認証キーを保存したファイルを用意したのであとはソースを書いてツイートを取得するだけです。
# -*- coding: utf-8 -*- from requests_oauthlib import OAuth1Session from searchtweets import ResultStream, gen_rule_payload, load_credentials from searchtweets import collect_results #-------------------- # Authentication #-------------------- #Authenticate Premium Search API premium_search_args = load_credentials("./twitter_keys.yaml", yaml_key="search_tweets_api", env_overwrite=False) #検索条件指定 #この場合だと「beyonce」について検索、という条件 rule = gen_rule_payload("beyonce", results_per_call=500) #Premium APIを使って「beyonce」について検索、検索結果のツイートを取得 rs = ResultStream(rule_payload=rule,max_results=1000,**premium_search_args) #取得結果をリスト化 tweets = list(rs.stream()) #取得結果出力 [print(tweet.all_text, end='\n\n') for tweet in tweets[0:10]];
取得例
Jay-Z & Beyoncé sat across from us at dinner tonight and, at one point, I made eye contact with Beyoncé. My limbs turned to jello and I can no longer form a coherent sentence. I have seen the eyes of the lord. Beyoncé and it isn't close. https://t.co/UdOU9oUtuW As you could guess.. Signs by Beyoncé will always be my shit. When Beyoncé adopts a dog 🙌🏾 https://t.co/U571HyLG4F Hold up, you can't just do that to Beyoncé https://t.co/3p14DocGqA Why y'all keep using Rihanna and Beyoncé gifs to promote the show when y'all let Bey lose the same award she deserved 3 times and let Rihanna leave with nothing but the clothes on her back? https://t.co/w38QpH0wma 30) anybody tell you that you look like Beyoncé https://t.co/Vo4Z7bfSCi Mi Beyoncé favorita https://t.co/f9Jp600l2B Beyoncé necesita ver esto. Que diosa @TiniStoessel 🔥🔥🔥 https://t.co/gadVJbehQZ Joanne Pearce Is now playing IF I WAS A BOY - BEYONCE.mp3 by ! I'm trynna see beyoncé's finsta before I die
BeautifulSoupでWebスクレイピングしてみた

今回はPythonのWebスクレイピングモジュール「BeautifulSoup(以下BS)」を使った、Webページのスクレイピングを紹介します!
準備
.py形式のファイルで使用するにはモジュールをインストールする必要があります。
以下のコマンドでインストールすることができます
pip install beautifulsoup4
またBSのメソッドを使うにはインポートする必要があるので、
pyファイルの先頭で
from bs4 import BeautifulSoup
と書くのを忘れないように!
使い方
def scraping(){ html = "<html>...</html>" soup = BeautifulSoup(html) }
ただしBeautifulSoup()はURLを引数として扱えないため、
urllib3などと組み合わせると任意のWebページのHTMLを取得できます。
def scraping(){ http = urllib3.PoolManager() r = http.request('GET', url) soup = BeautifulSoup(r.data, "html.parser") }
これで変数soupには取得したHTMLが格納されています。
- aタグを全て取得したいとき
例えば取得したHTMLに含まれるaタグを全て取得したい時は
data = soup.find_all('a')
とすることで取得できます。
また
data = soup.find('a')
もしくは
data = soup.a
とすることで指定タグの先頭だけ取り出すことができます。
以上がBeautifulSoupを使ったWebスクレイピングのご紹介となります。
詳しくはkondou.com - Beautiful Soup 4.2.0 Doc. 日本語訳 (2013-11-19最終更新)をご覧ください
jQueryで指定要素以外の要素をクリックした時の処理を書く

1. 概要
表示中のプルダウンを、プルダウン以外の場所をクリックしたらプルダウンを非表示にする
という処理をご紹介します。
文章だけだとイメージしづらいので、Excelを例にすると、
「検索と選択」というメニューを表示中に
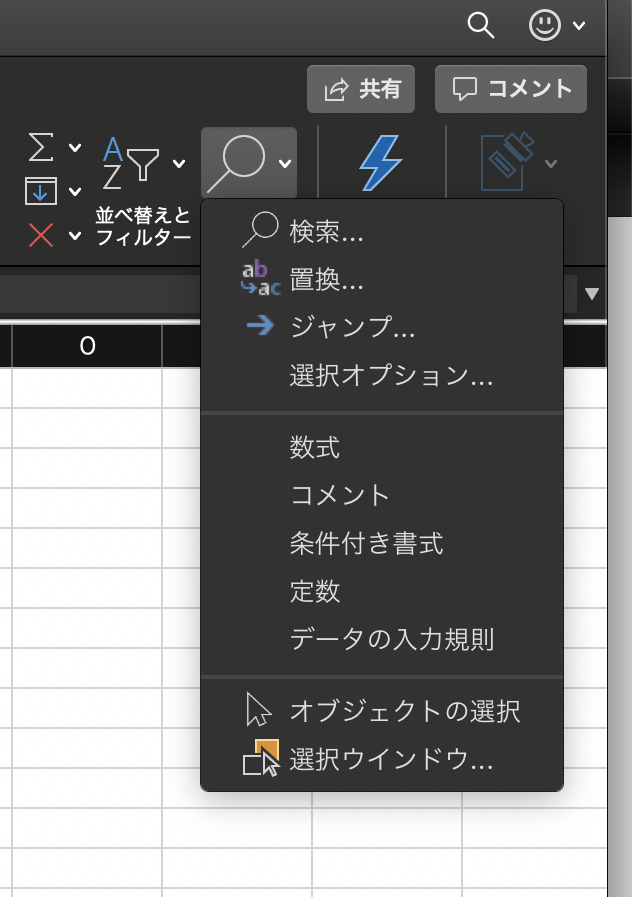
別の場所をクリックすると表示していたメニューが消える

みたいな処理をjQueryで書いてみました。
2. 処理の流れ
コードをご紹介する前に、
先ほどのExcelのプルダウンを例にして、どのような手順で処理をしていくかを説明します。
1. 全てのクリックイベントを取得
2-a. クリックした要素がプルダウン以外の時の処理
2-b. クリックした要素がプルダウン内の時の処理
これを元にコードを書いていきます!
3. コード
2.でご紹介した処理を元に書いたコードが以下のようになります。
$(document).click(function(event) { if(!$(event.target).closest('#targetId').length){ //プルダウン範囲外の処理 } else{ //プルダウン範囲内の処理 } });
1. 全てのクリックイベントを取得
$(document).click(function(event) {
ソースを読み込んだファイル全体のクリックイベントを取得します。
$(event.target)でクリックしたイベントそのものを取得することもできます。
2-a. クリックした要素がプルダウン以外の時の処理
if(!$(event.target).closest('#targetId').length){
※ここではプルダウンのソースがhtmlだと仮定します。
closestメソッドを用いることによって、クリックした箇所に最も近い指定要素かどうかを判定します。
closestメソッドは要素が見つかった時点で探索を終了するため、parentsメソッドよりも処理時間が早いです。
2-b. クリックした要素がプルダウン内の時の処理
割愛
4. まとめ
以上が指定要素以外の要素をクリックした時の処理でした。
ざっくりまとめると、
1. 全てのクリックイベントを取得
2. 指定要素かどうかを判定
という流れです。